Today i want to share a story about how i ended up writing a simple process tracer for linux. Using eBPF in go to fix a github actions which i actually didn’t need. We will go over each piece and hopefully you will learn something form it.
Todays characters are ‘Boris The Boss’ the part of me which keeps my distractions in check, and Bobby the curious sidekick which doesn’t understand the concept of time… Bobby and Boss don’t get along and i’m one between the crossfire.
The story begins with curiosity about why our main CI pipeline took two minutes to complete.That felt too long, considering how often our team runs it. Optimizing it it could save us time and allow us to extend how much we can test. So i wanted to know are we limited by the CPU or the Memory?
Bobby: There’s got to be a github action for this! Hey, Lets have a look at workflow-telemetry-action It even promises to show a graph to show the runtime of each processes:
Ah cool lets try it out it will not take that much time to add it to the build. But the graph didn’t work… But the CPU and memory wasn’t saturated so i guess the build can be made faster.
Bobby: Well, since our script is already golang based and the process we call is also golang, can’t we directly integrate it in the script. We can then profile the script. So i ran the profiler using:
| |
Source and more info about profiling
The root cause where some inefficient code paths in helm. Like an inefficient regex and a slow parsing of the yaml indexes for the helm charts. This reduced the runtime from 20s to 4s resulting in a final build of around 1minute. Locally on a computer with a hot cache it now runs in seconds.
BOSS: back to work you two
So i guess this is wrapped up, But several days later Bobby wasn’t ready to let it go.
Bobby: Come on, you’re a senior engineer! There must be a way to fix that Github Actions.
Aren’t you curious on how it works?
Ah well lets have a look at how this thing works, it seems they use a binary to do the process tracing hopefully they host the source somewhere. But sadly there isn’t as confirmed here.
Begin of the Journey: Reverse engineering
So i downloaded the binary and had a look inside it. The strings command allows us to have a peek inside, It only prints the readable strings in the binary. So looking through the output:
| |
To bad that the full piece of code isn’t in here, but it is enough to get us started. The logic didn’t look overly complicated, so maybe i can try to recreate it myself.
Note when you do strings on a go binary, often there is a major part of the source included in there because it is used for debugging.
Bobby: This is clearly some C code in the binary, what is this ’eBPF’ thing?
tp/sched/sched_process_exec
And so we descend into the rabbit hole of ebpf, since we already fixed the CI performance, we saved enough time to learn something new.
The Spiral into eBPF
So what is BPF? Mmmm, interesting an package filter to setup some networking firewalls and have direct control over the ip packages received. This could be so handy for one of our other projects.
BOSS: back to eBPF you two Right.extended BPF (eBPF) this seems what we need. It takes the idea of BPF a step forward and allows us to hook our usercode directly into the kernel. Our hook needs to be a very strict subset c code. This then gets loaded into a VM and run in kernel space. We can then select which functions of the c code we hook to which tracepoints. Tracepoints are exposed events put in place by the kernel developers. It was originally used to debug the kernel but it now has grown to allow for a lot more observability tools. An example of a tracepoint is on receive of an IP packet, any file interaction, thread rescheduling etc. There are really a lot of tracepoints.
Using our C code we can then expose events from kernelspace directly to userspace which is on one hand unsafe but on the other hand its also super powerful. We also have to be careful not to crash our system. Hence why it is such a strict subset of c.
Looking at the eBPF website there are multiple tools written with eBPFmultiple tools suggested.
Bobby: Oh cool Parca, Pyroscope, which allows for continuous profiling. They indeed look very impressive it would allow us to track the performance far beyond what a simple proc-tracer would give us. It would be able to show us a full flamegraph like the profiling of our go script, But then for the whole build. Image the insights we would get when we profile our full test suits and then we can pinpoint what is slow in all our builds.
Four hours later… Reality stuck. This kind of setup wouldn’t work since i don’t have the infrastructure of a big company. There aren’t any options to save the profiling data as a pprof or open-telemetry file.
BOSS: How is the proc-tracer coming along?
Right. Back to the task at hand, i’m not a kernel hacker so i guess i’ll have to read a lot of documentation.
Bobby: Can’t we have another peek into the binary?
Good idea here are the tracepoints we will use:
| |
Gearing up with the EBPF tools!
So we had another look at the eBPF website and we found several useful tools:
The first contender is bpftrace, A powerful CLI made to investigate kernel traces. But since it came with its own DSL (Domain-Specific Language), and i wasn’t keen to learn new language just for this task. Plus, I had no interest in writing my complex bash script to glue everything together.
The next option BCC this is a python based library designed for eBPF tooling and scripts. but distributing a python based tool is kind of a nightmare. Yes i know there is pipx, but we will then have to install python and all the dependencies and maybe even the kitchen sink, i.e. an llvm compiler. But on the plus side i found the exitsnoop example which already does wat i wanted. So i can take the c code from there.
So, to keep the distribution simple a single binary would be idea. So i’m left with C/C++/Rust/Zig or Golang. Since the simplicity of the tool, I choose Golang.
So lets have a look for golang eBPF libraries:
- https://github.com/iovisor/gobpf Requires CGO
- https://github.com/aquasecurity/libbpfgo Requires CGO
- https://github.com/cilium/ebpf Aha this one doesn’t need CGO
In Go, avoiding CGO is generally advisable. CGO adds complexity by requiring Go to follow C conventions, leading to unrelated problems and making builds far more difficult.
Some people, when confronted with a problem, think “I know, I’ll use CGO.” Now they have two problems.
So, I landed on cillium/ebpf. It avoids CGO and it generates the necessary gluecode for me form the C code. I had a few looks at the examples to understand how it works. Like this one which also almost does what i need.
The actual implementation
So after reading the documentation.
And looking at the examples i decided to go for these tracepoints instead: execve sched_process_exit
To see the structure of a tracepoints you can do this:
| |
C time
With the basic setup i started with the communication between the Go code and the C code. This is done using MAPS which can be an arrayMap, hashmap and ringbuffer.
The ringbuffer example looked the simplest and ideal for my usecase.
We will make the hooks communicate over a ringbuffer using events.
So first the ringbuffer:
| |
Looking at the C code of the binary and the example we is a crucial type missing, the task_struct, where does it come from?
| |
Bobby: Lets search all of github!!! Good idea i found [something].(https://github.com/castai/kvisor/blob/d296feebd15e7bb3c0626ec62083c88db81c0ddc/pkg/ebpftracer/c/tracee.bpf.c#L46)
So it seems we need the vmlinux.h header, after some searching i found out we can use bpftool to generate this:
| |
Now that we know the types we can start writing the hooks, Lets start with the messages which we will send over the ringbuffer.
Lets start both events with a header containing event_type and pid. This will make it easy to select the right decoder for the event.
| |
Now the actual logic of the c program.
The first handler is called when a program is started by the kernel, lets go over it step by step (read the comments):
| |
Why do we send one event per argv wouldn’t it be a better idea to send all of them?
Yes that was my original idea, the problem is that argv is an array of string and this has multiple drawbacks:
- The struct needs to have static size and thus to fit all the args it has to be very big.
- The validator checks that we don’t copy too much data in a single step causing a rejection of the program. So its is just easier to allocate 1 event per argv.
Now the second tracepoint, its a bit more complicated, It gets called any time a thread exists or when the program exits, this is when the main thread exists:
| |
So now that we have a command end event and know the start time, end time and exit code we can start writing the go code:
Go time
To set up the code generation we will have to run the bpf2go command. Luckily go provides us with some code generation tool out of the box using go generate ./....
It works by scraping files for ‘magic’ comments starting with //go:generate and it automatically downloads the needed tool.
So to the main file i’ve added:
| |
This will instruct bpf2go to generate code for both of the even types it also generates hooks for each c function in the file.
| |
Next, we need to set up the Go side to decode the events from the ebpf process. Since we send two types of events we will first look at the first byte, i.e. the header, to decide which decoder to use:. Let us go over the code together:
| |
So finally the moment of truth:
| |
Bobby: i’m tired; can we go to sleep now? No Bobby, you started this now we will have to pull it to the end!
Fixing the action
It seems the action is written in typescript like most actions, scrolling trough the code yielded with the required json format. Which is actually read from a file. (source)[https://github.com/borissmidt/workflow-telemetry-action/blob/master/src/interfaces/index.ts#L95-L105]
| |
The original implementation did some processing of the event which i removed since i already do it in the go code. So to export the json i added this struct and added a file writer:
| |
The rest of the code starts the binary with an output file and it ads a post hook to parse the file.
To simplify my development cycle i installed bun and changed the script to be able to run it locally.
Bun allows you to directly run the typescript code.
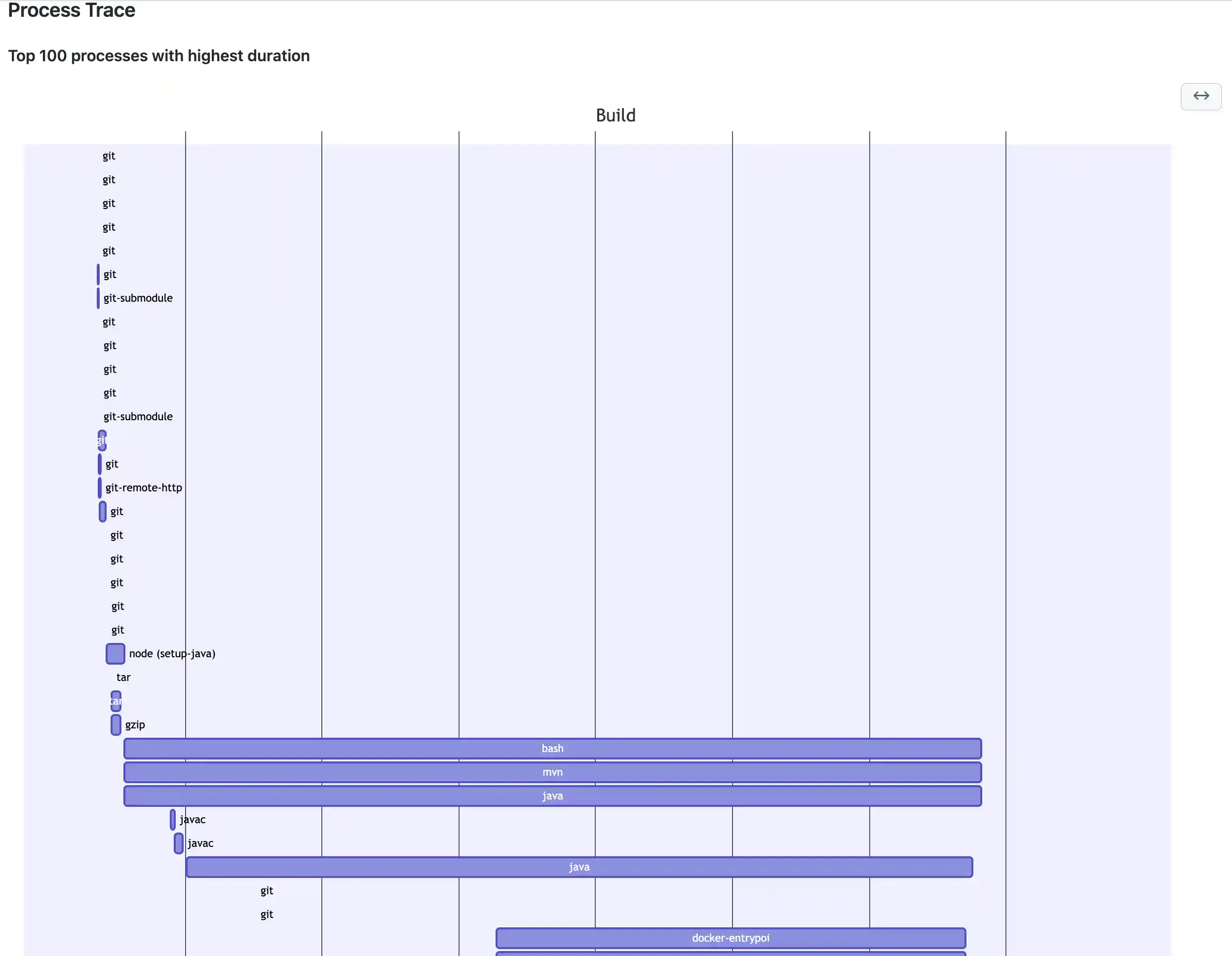
Then it generates a gant output and prints a list:
So did this work? YES
Conclusions
Writing an eBPF program to track system events is manageable when the task is simple, but it can quickly become challenging if you’re not familiar with kernel-level concepts. Much of the difficulty comes from “fishing” for examples and documentation, especially when the details you need aren’t readily available. Without background in Linux internals, it’s easy to get bogged down since you will sometimes have to go directly to the kernel code. It is also recommended to have a basic knowledge of embedded programming since it is important to optimize the code otherwise the validator will not allow you to register the epbpf hooks.
Ideally github actions should fix its stuff and provide metrics, ideally continuous profiling, to the actions runner. Hey they could even sell this as a feature to there customers. The bare minimum they should provide is an overview to see how many actions failed and a graph on how long they took. This would already be valuable to see which ‘commits’ slowed down the build. Allowing us to speed up the build. But since github earns money on the actions they don’t seem to care.
Some paid tools that can help:
- gh-action-stats
- datadog
- honeycomp
- roll your own
References:
- cillium ebpf getting started
- application written using ebpf https://ebpf.io/applications/
- https://github.com/iovisor/bcc
- https://github.com/bpftrace/bpftrace
- syscalls https://man7.org/linux/man-pages/man2/syscalls.2.html
- more info about ebpf from datadog
- awesome ebpf
Being destracted by life
Let us have a look at those syscalls, thank you Filippo Valsorda, I envy your the drawing of the bridge you have.
Bobby: it reminds me of EURO bills Ah let me look at that… Hey non of the bridges match, do they even exists? one hour later I’ll have to make another trip to the netherlands with my wife…